Distributed cache, YesSql improvements - This week in Orchard (09/10/2020)
Get ready for the upcoming additions of Orchard Core! This week you can see demos about adding distributed cache to Orchard Core and the latest improvements of YesSql!
Orchard Core updates
Restrict Content Types Admin Node to only create the specified content type
Let's say you have a site set up with the Blog recipe and your goal is to add a new admin menu that is about to list all the existing Article content items. To do that you have to navigate to Configuration -> Admin Menu and click on the Add Node button. Here you will need to select the Content Types Admin Node because you would like to add a link for each one of the selected content types from the list. And yes, you will only select the Article content type in the next screen. And that's it, you have created a new admin menu that lists all of the Article content items from the system. If you click on that you will see the list of the Article content items. Note that from now you will not see a filter here to filter by content types because that really doesn't make much sense. You created this Content Types Admin Node to list only the Article content items. If you would like to filter by content type, use the filter in the Content -> Content Items page as you would do it before.
Remove ManageOwnMedia permission
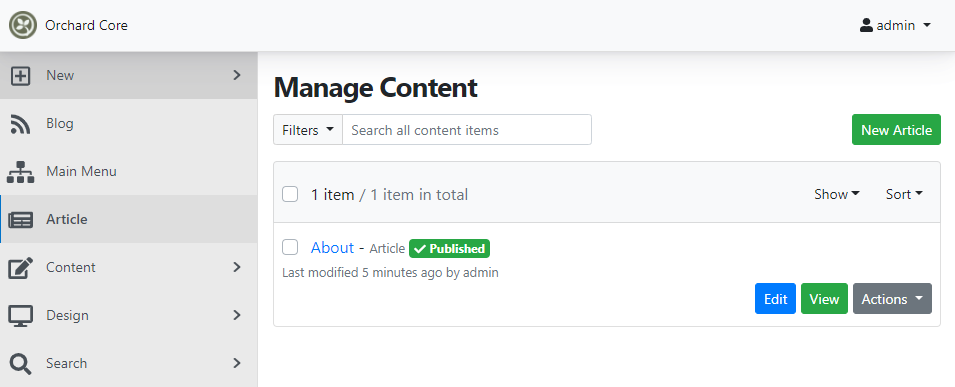
The ManageOwnMedia permission isn't handled today and we can replace it with the ManageMedia permission. So, now there is no separate permission to manage their own media or manage the media. It will be added back to the system again if the authorization logic is to be able to separate the user's media and the media uploaded by others.
Right now, if you head to Security -> Roles and hit the Edit button near one of the Roles, you will see the missing Manage Own Media permission.
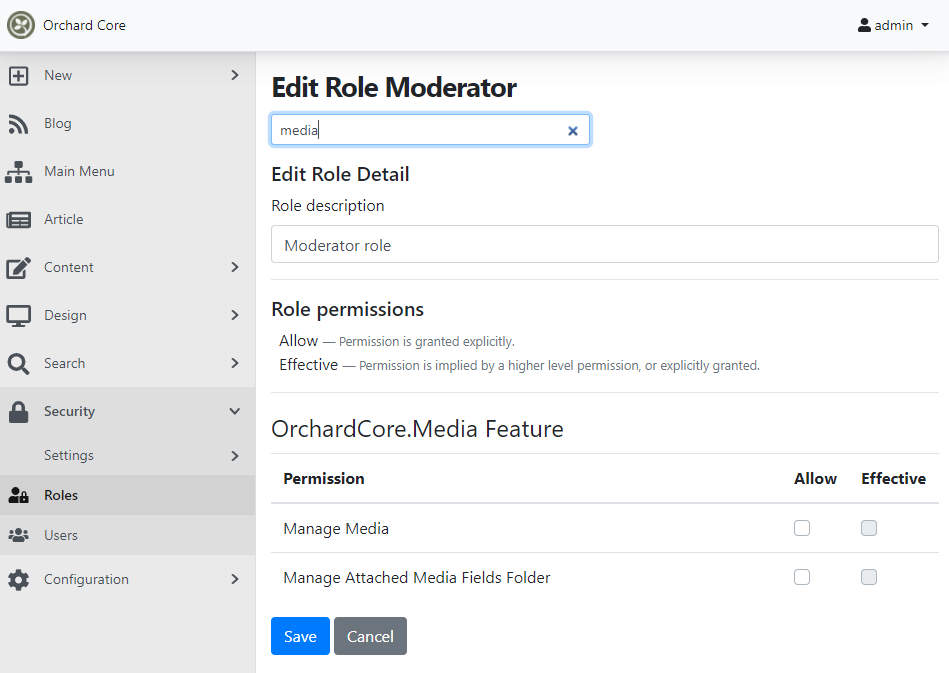
Use a dropdown menu on the admin top navbar for the user menu
The user menu on the admin theme is just about listing the user name of the currently logged-in user with a little icon near it. And there was a Log off link at the right side of the user name. It was just a piece of HTML code in the Layout.cshtml file of the default admin theme. From now the whole user menu gets its own shape, called UserMenu.cshtml. If you would like to override the user menu, you don't need to create a Layout.cshtml file in your admin theme, you just need to override the UserMenu.cshtml file.

And if you check out this GIF, you will see that now the content of the user menu is placed in a dropdown instead of having it's content inline.
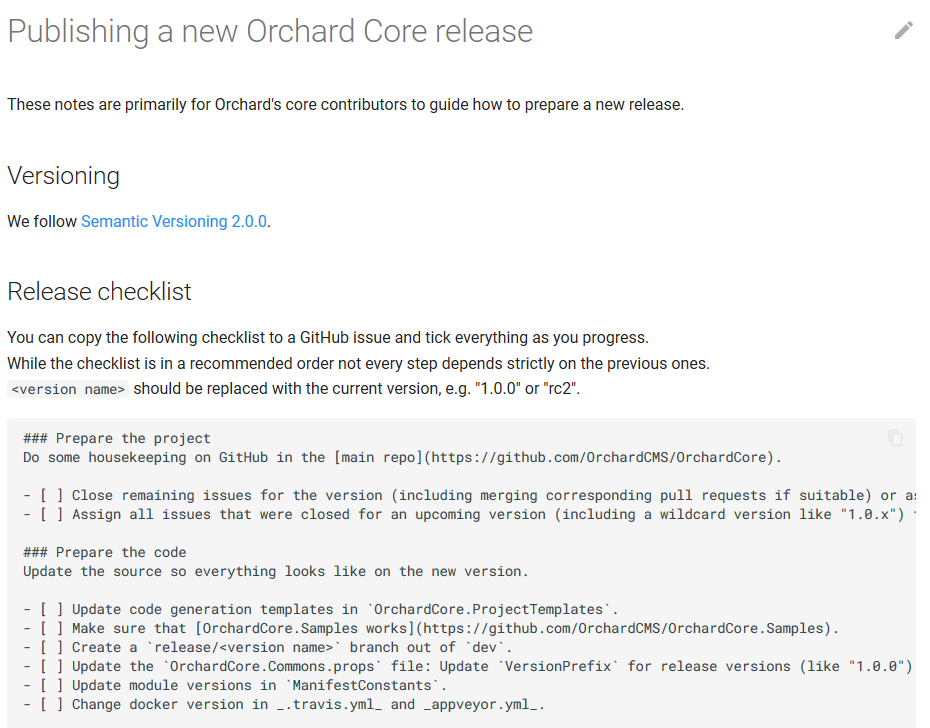
Document release procedure
Orchard Core is open-source that means you can check out and request changes to the source code, tell your opinion about it, and update the relevant documentation for that piece of code. Now there is a new page in the Orchard Core Documentation about how to publish a new Orchard Core release. These notes are primarily for Orchard's core contributors to guide them on how to prepare a new release, but if you just take a look at these you can now see what are the steps that need to be done to be able to ship a new release of Orchard Core.
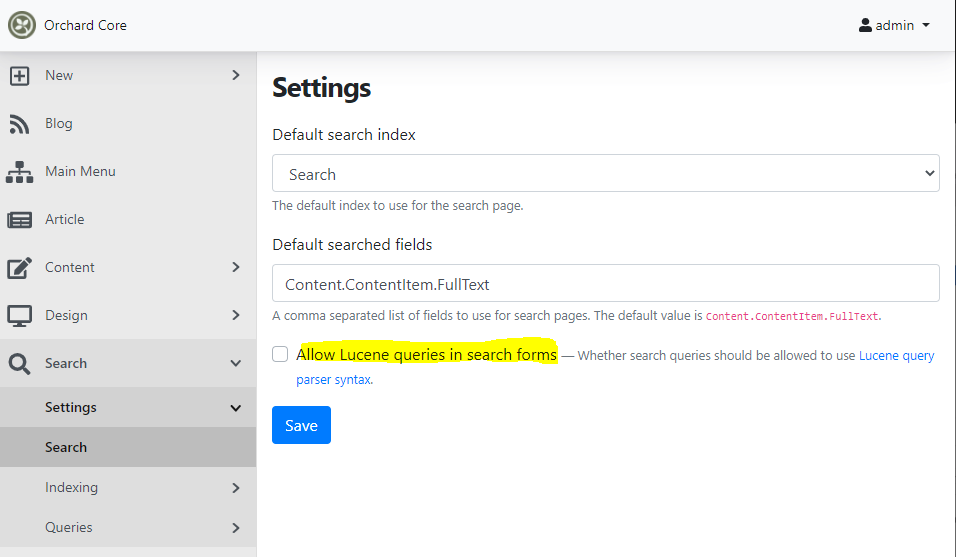
Add option to allow Lucene query syntax in the search
There is a setting in the Lucene module that you can turn on and whatever you type in the search box won't be parsed as 'these are the words that I need to search on', but parsed as this is a Lucene query. You can use the Lucene query syntax in search forms, like the quotes, plus signs and things like this. But by default, it will still be like today, which is type words and it looks for these words. If you type stuff that has weird characters, they would be ignored.
But how can I turn on that feature? Just navigate to the admin UI of Orchard Core, then find the settings in Search -> Settings -> Search (make sure you have enabled the Lucene module).
Demos
YesSql: Adding support for multi filters on the same table index
There is a new method on .IQuery called .Or(), which starts a filter on a distinct table. This can be used for instance when the same index needs to be queried for multiple sets. It will actually add many filters on the same record of the index. With .Or() you can do now filters on different inner joins of the same index. Which means it will do unions of result with the filters. Let's check out the following unit test.
[Fact]public async Task ShouldQueryMultipleIndexes(){// We should be able to query documents on multiple rows in an index.// This mean the same Index table needs to be JOINed._store.RegisterIndexes<PersonIdentitiesIndexProvider>();
using (var session = _store.CreateSession())
{
var hanselman = new Person
{
Firstname = "Scott",
Lastname = "Hanselman"
};
var guthrie = new Person
{
Firstname = "Scott",
Lastname = "Guthrie"
};
session.Save(hanselman);
session.Save(guthrie);
}
using (var session = _store.CreateSession())
{
Assert.Equal(2, await session.Query<Person>()
.With<PersonIdentity>(x => x.Identity == "Hanselman")
.Or()
.With<PersonIdentity>(x => x.Identity == "Guthrie"))
.CountAsync());
}
}
This PersonIdentitiesIndexProvider will just map the first name and the last name of each person. We created two persons here that means the provider will be creating four PersonIdentity records. Two to store the first name and last name for Scott Hanselman and two to store the first name and the last name of Scott Guthrie. If without using the .Or() it will issue a query where the Identity == "Hanselman" AND Identity == "Guthrie", which will return nothing. With the .Or(), it will do an inner join on PersonIdentity with a filter on Identity == "Hanselman" and another inner join on PersonIdentity with a filter on Identity == "Guthrie". In this case, we will get both the two persons. It's like give me any person who's PersonIdentity has a record like Hanselman OR where the PersonIdentity equals Guthrie. Let's see another example!
// Creating articles.using (var session = store.CreateSession()){session.Save(new Article { Content = "This is a green fox" });session.Save(new Article { Content = "This is a yellow cat" });session.Save(new Article { Content = "This is a pink elephant" });session.Save(new Article { Content = "This is a green tiger" });}using (var session = store.CreateSession())
{
Console.WriteLine("Boolean query: 'pink or tiger'");
var boolQuery = await session.Query<Article>()
.Where(x => x.Word.IsIn(new[] { "pink" }))
.Or()
.Where(x => x.Word.IsIn(new[] { "tiger" }))
.ListAsync();
}
This is a full-text sample where in this case we can query documents by their content, by their words. If we have the documents as you could see in the code, we are creating an index for all the words pointing to the document, like green and fox points to the first Article. Now the query is about to give me all the documents that have pink in it OR all the documents that have tiger in it. The goal is to get the last two articles in this case.
Let's check out this query:
var boolQuery = await session.Query<Article, ArticleByWord>().Where(a => a.Word.IsIn(new[] { "white", "fox", "pink" })).ListAsync();This query will return all the articles that have white AND fox AND pink in it and there is none in this case. You can find the recording of this improvement on YouTube!
But wait a minute! Could this syntax be better? When you have a query, you can say .Any() and every predicate will be done in a different table. .Any() being an OR, and .All() being an AND. In this case, we're querying on the same index (ArticleByWord) but each of the calls on .With() will be a different projection, a different inner join in this case.
Here we are looking for an article that has the word pink OR the words green AND fox.
await session.Query<Article>().Any(x => x.With<ArticleByWord>(a => a.Word == "pink"),x => x.All(x => x.With<ArticleByWord>(a => a.Word == "green"),x => x.With<ArticleByWord>(a => a.Word == "fox"))).ListAsync();
SELECT DISTINCT Document.* FROM DocumentINNER JOIN ArticleByWord_Document AS [ArticleByWord_Document_a1] ON ArticleByWord_Document_a1.DocumentId = Document.IdINNER JOIN ArticleByWord AS [ArticleByWord_a1] ON [ArticleByWord_a1].Id = ArticleByWord_Document_a1.ArticleByWordIdINNER JOIN ArticleByWord_Document AS [ArticleByWord_Document_a2] ON ArticleByWord_Document_a2.DocumentId = Document.IdINNER JOIN ArticleByWord AS [ArticleByWord_a2] ON [ArticleByWord_a2].Id = ArticleByWord_Document_a2.ArticleByWordIdINNER JOIN ArticleByWord_Document AS [ArticleByWord_Document_a3] ON ArticleByWord_Document_a3.DocumentId = Document.IdINNER JOIN ArticleByWord AS [ArticleByWord_a3] ON [ArticleByWord_a3].Id = ArticleByWord_Document_a3.ArticleByWordIdWHERE ArticleByWord_a1.Word = 'pink'OR (ArticleByWord_a2.Word = 'green'AND ArticleByWord_a3.Word = 'fox')
Here you can also see how does the query look like. That's the current syntax right now. And it's not breaking change because if you had .query.With().With(), it will still behave the same as before. It will be a single projection with two .With(). If you project on the same table it will be an AND on the same table, the same projection.
If you would like to know more about the current syntax and the latest features, this is the YouTube video that you are looking for!
Distributed Redis Cache
There is a huge PR with a great addition to Orchard Core about having Distributed Cache in Orchard Core.
In fact, this PR is related to all modules services using cached data that need to be in sync with a shared database, e.g. site settings and other admin settings, templates, queries, layers, and so on. Currently, in the dev branch, this is already the case for most of them but by using local memory cache entries that are invalidated through a distributed signal.
This PR has changed this pattern by using a multi-level cache including a distributed cache. And Jean-Thierry Kéchichian made more services to be distributed aware, there are remaining things but could be done in other PRs. And recently he added the ability through a separate feature to also keep in sync tenant states, when you enable/disable/create/setup a tenant.
To summarize:
- All services that were using the memory cache are now using a multi-level cache including a distributed cache, this cache is kept in sync with the database without using a message bus but document identifiers.
- We have concrete implementations of distributed services based on Redis, Redis cache, Redis data protection, Redis message bus, and Redis lock. In the current code, we never use a message bus/distributed lock.
- When enabling a concrete distributed cache in the default tenant, we automatically keep all tenants in sync through a hosted service, here also without using a message bus but identifiers. Here a stateless configuration is needed.
- There is a separate feature (DefaultTenantOnly) to keep tenants in sync.
Don't forget to head to YouTube and watch the recording of this upcoming feature!
News from the community
Orchard Dojo Newsletter
Lombiq's Orchard Dojo Newsletter has 160 subscribers! We have started this newsletter to inform the community around Orchard with the latest news about the platform. By subscribing to this newsletter, you will get an e-mail whenever a new post published to Orchard Dojo, including This week in Orchard of course.
Do you know of other Orchard enthusiasts who you think would like to read our weekly articles? Tell them to subscribe here!