Prevent Trumbowyg from converting <div> to <p> element, Elasticsearch feature - This week in Orchard (26/08/2022)
Prevent Trumbowyg from converting <div> to <p> element, reduce memory when reloading settings of a given tenant from the database, and a demo about the upcoming Elasticsearch feature! Let's get started!
Orchard Core updates
Prevent Trumbowyg from converting <div> to <p> element
When using HtmlBodyPart or HTMLField with either WYSIWYG or Trumbowyg, the editor converts <div> elements to <p>. Also, when the user switches into code insert mode, the text area does not take up the full size of the editor.
Steps to reproduce the behavior:
- Add HtmlBodyPart or HtmlField to a content type, and use either WYSIWYG or Trumbowyg editors.
- Create new or edit an existing content item. Click on <> of the editor to switch into code insert mode and insert the following.
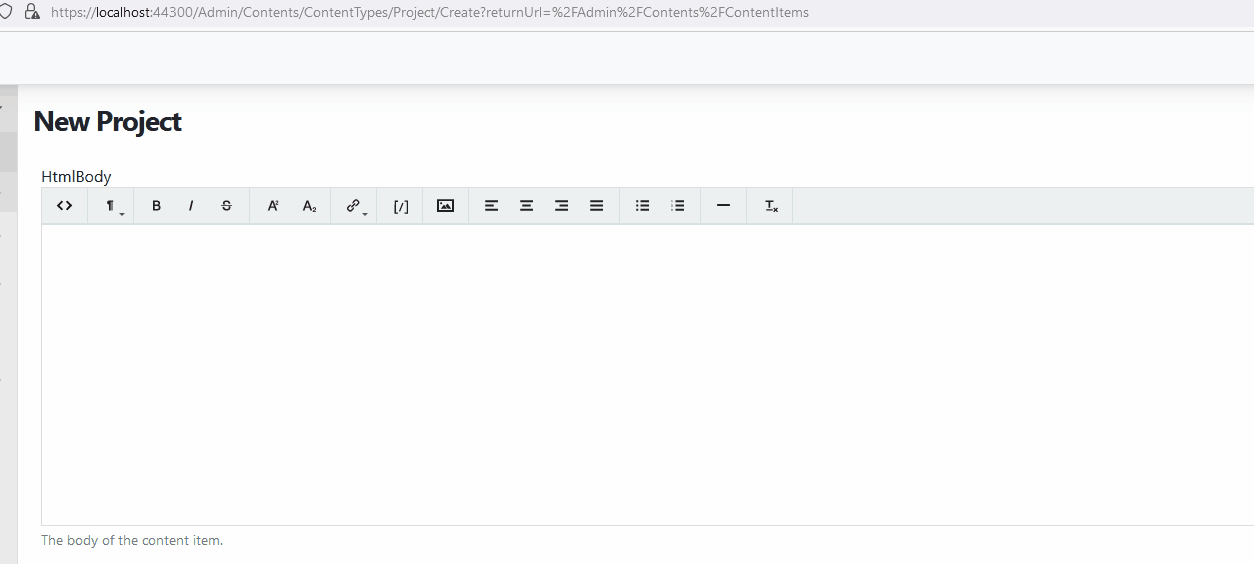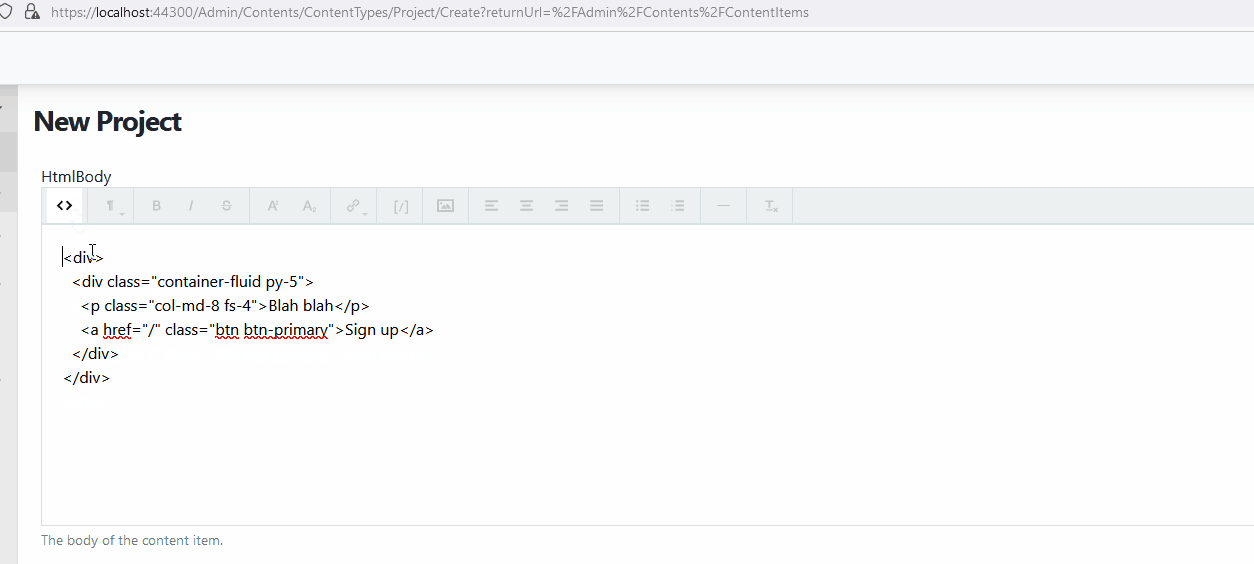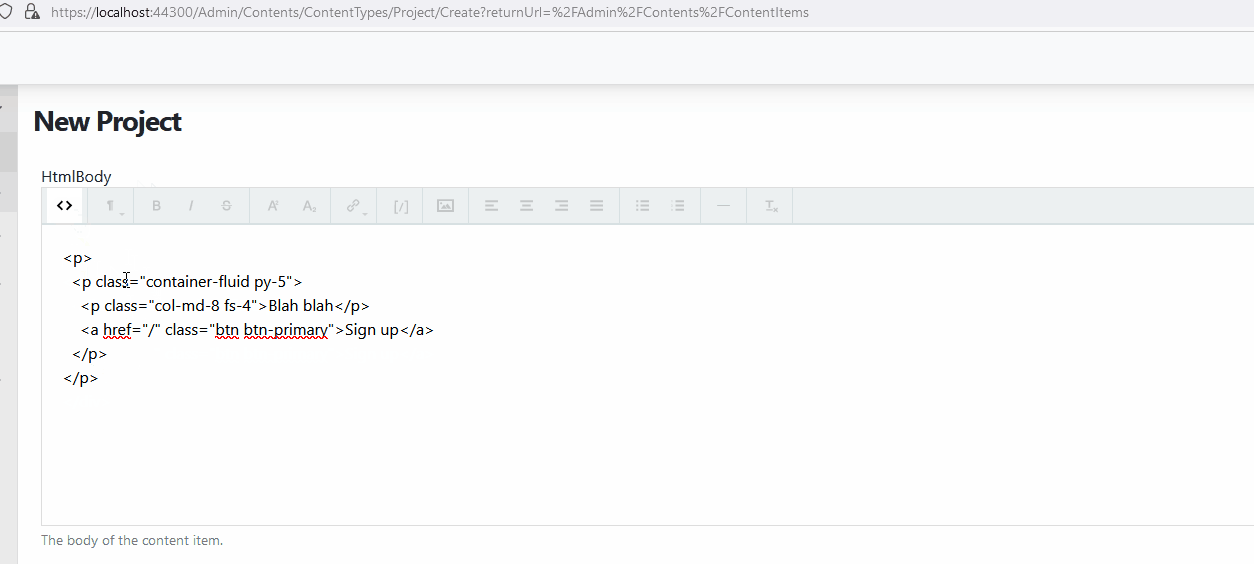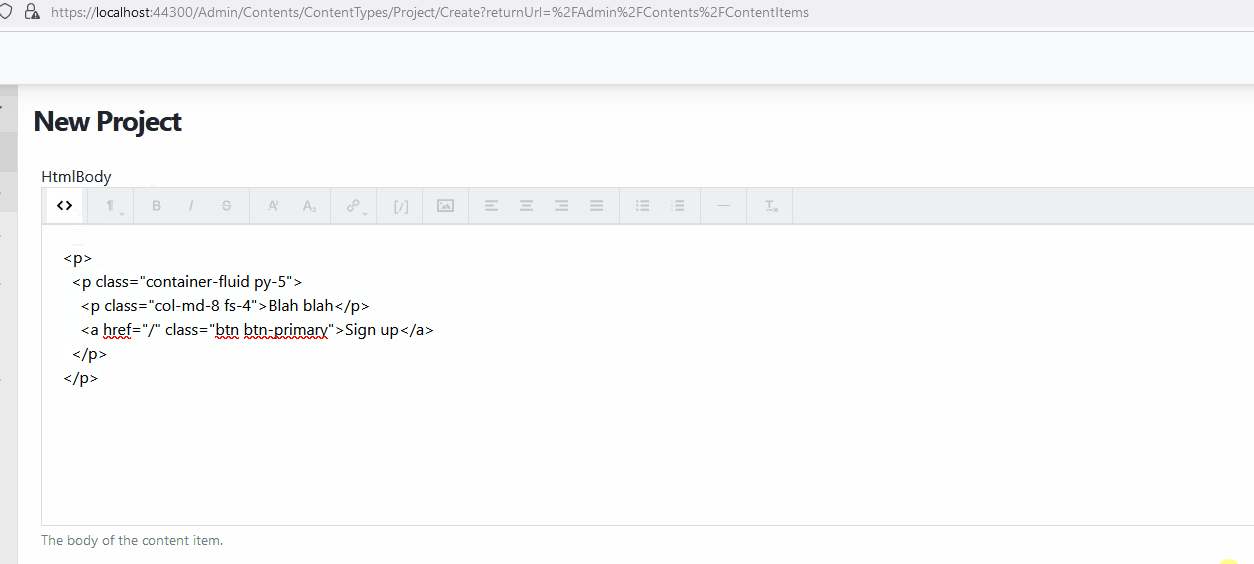
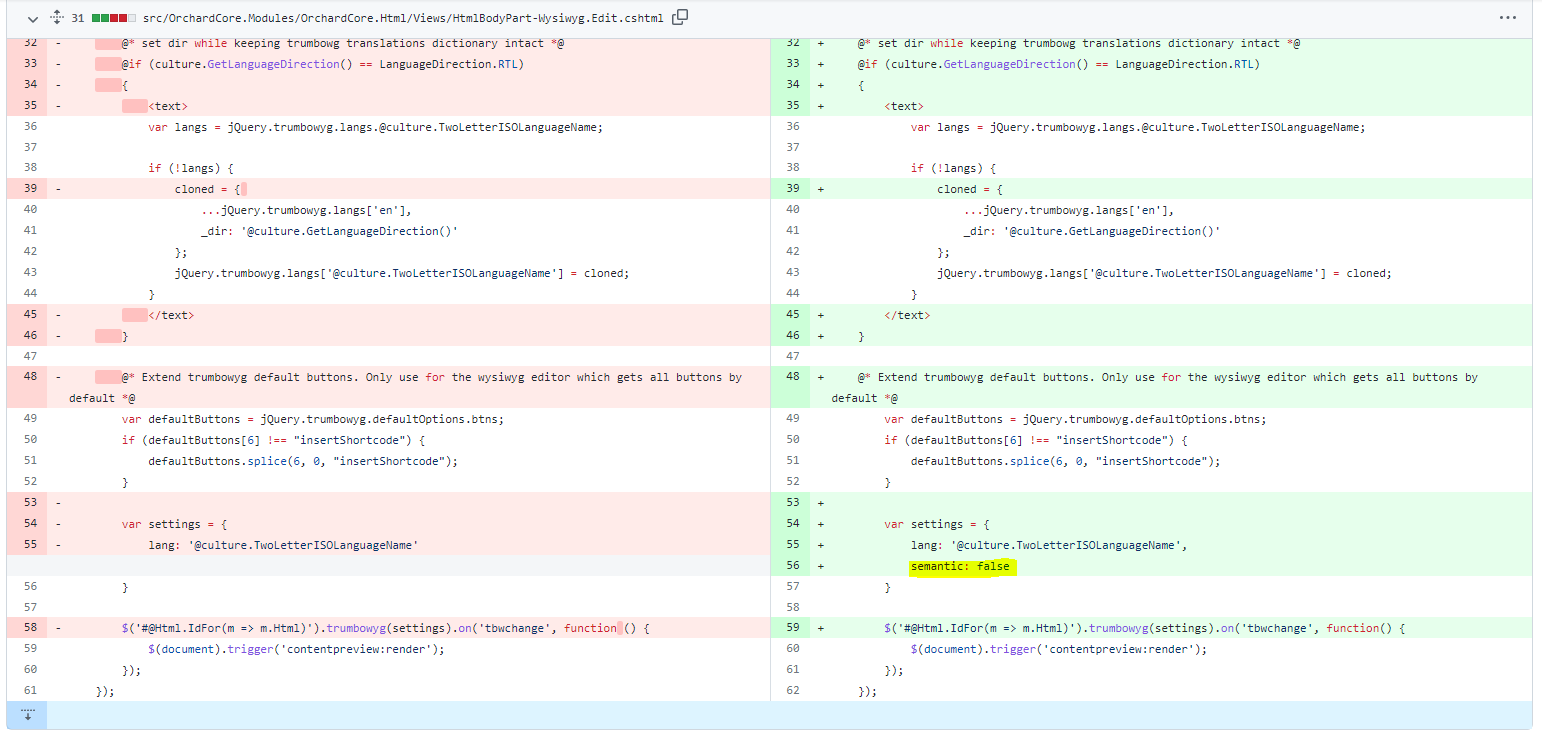
The issue is that the Semantic option is enabled by default. By enabling Semantic, it generates a better, more semantic-oriented HTML (i.e. <em> instead of <i>, <strong> instead of <b>, etc.), meaning:
$('.trumbowyg').trumbowyg({semantic: {'b': 'strong','i': 'em','s': 'del','strike': 'del','div': 'p'}});
The idea is that the "Wysiwyg" editor option should not alter the "Tryumbowyg" editor default behavior. This is why we have the "Trumbowyg" editor option that allows changing its behavior for your own needs. So, the fix was to set the semantic: false on the Wysiwyg templates and don't change anything on the Trumbowyg templates.
Reduce memory when reloading settings of a given tenant from the database
There appears to be a memory leak caused by the usage of IConfiguration as the backing for ShellSettings. Memory used by each ShellSettings instance is not being freed for garbage collection due to some fairly crazy gcroots even if you intentionally release the ShellSetting.
Most of the memory is being used by Strings related to the DatabaseShellsSettingsSources with the VersionId field being the largest consumer of memory. The problem is that the DatabaseShellsSettingSources contains data for ALL tenants (which can be 2000+ in some cases) even if you're only loading/reloading a single tenant.
So, among our tenant config/settings sources, one of them is by default the tenants.json file. In fact, when we reload a given tenant, we don't need all data from this source but only those related to this tenant.
When we add this source to the config stack of a given tenant, if we still use builder.AddJsonFile() we have no choice, we can't split this file into smaller parts per tenant.
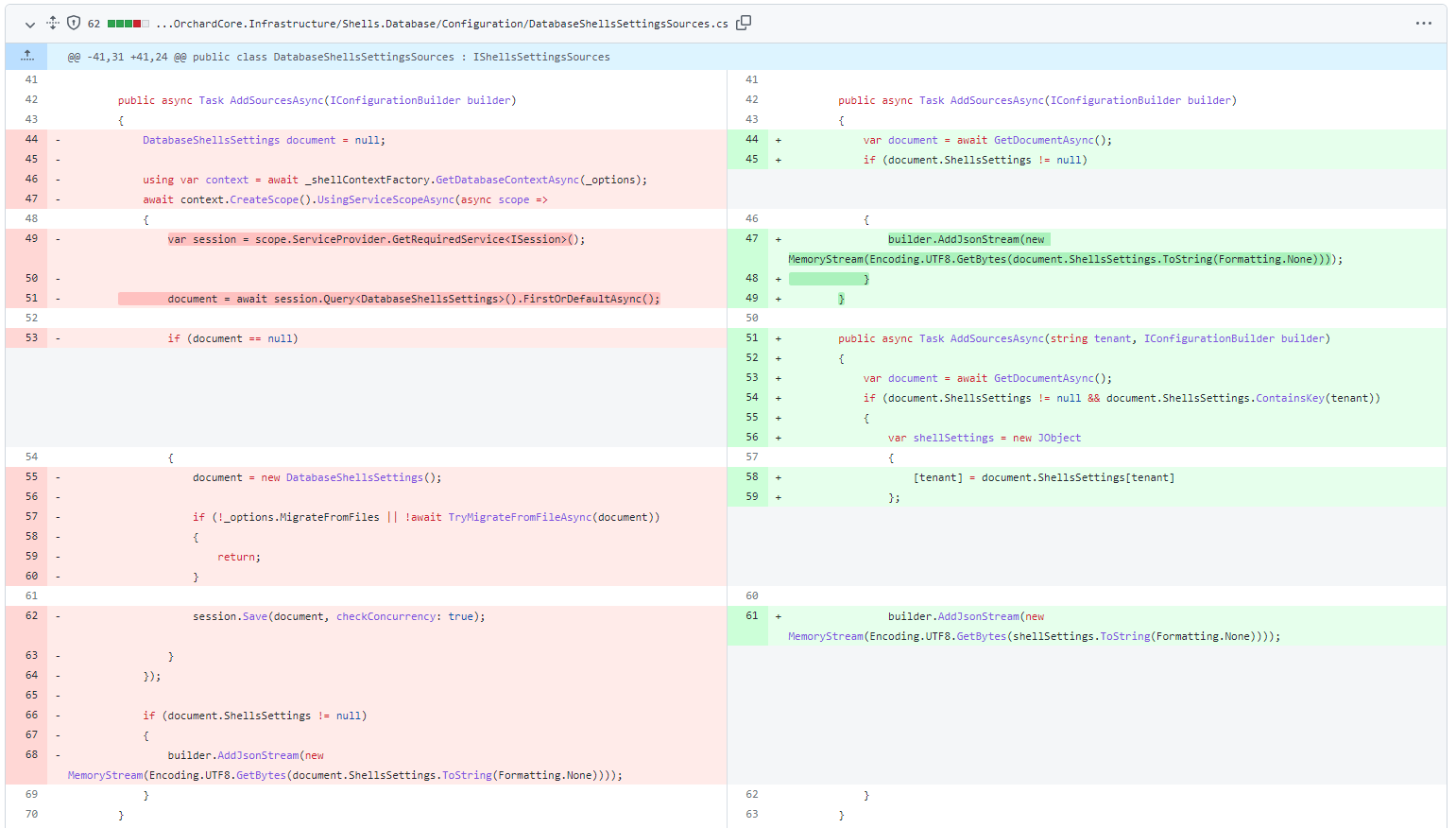
But when this source comes from the database, we do a builder.AddJsonStream() on a MemoryStream that holds all data of this source, so here the idea is to only hold in memory the data related to this tenant.
To do so Jean-Thierry Kéchichian added a method to the interface of this source allowing to pass a tenant name.
So that when the source comes from the database, each time we reload a specified tenant we still create a MemoryStream but that only holds the data related to this tenant (not all tenants).
When calling this new method on the other implementations of this source, they just ignore the provided tenant name by calling the existing method without this parameter.
Demos
Elasticsearch feature
Elasticsearch is a search engine based on the Lucene library. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents. This time we will see how you can use Elasticsearch in Orchard Core using the Elasticsearch feature, which can be found in this pull request and will be released soon. The Readme.md file of the module describes how you can use this feature for development and testing purposes by using Docker. We won't go into the details of how to install Docker and use the Docker Compose file, the Readme.md file mentioned has a nice step-by-step tutorial about that part.
So, let's say we have a Docker container running the Elasticsearch image on port 9200 (the default one). The Elasticsearch module connection configuration can be set globally in the appsettings.json file or per tenant.

The connection types documentation and examples can be found at this URL.
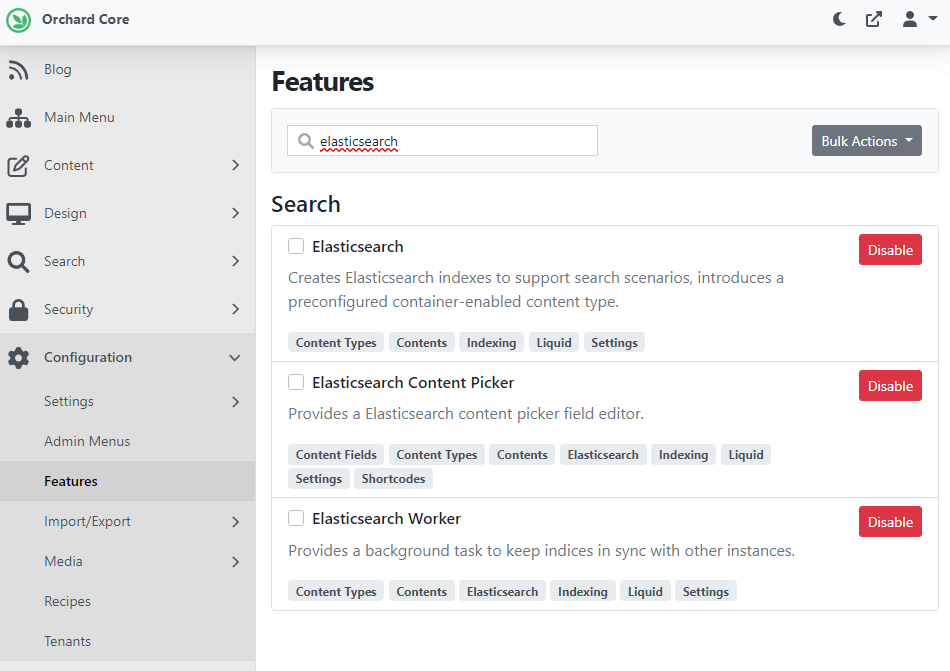
To try out this feature, you need to enable the Elasticsearch feature under Configuration -> Features. You can also see a Content Picker for Elasticsearch, just like we have for Lucene, and a Worker. And of course, don't forget to enable the Search module as well, which adds front-end search capabilities. We will use this feature to try out the new Elasticsearch feature.
The Elasticsearch module has some settings in the admin, where you can configure the search settings for the module (Search -> Settings -> Elasticsearch), and you can decide which fields you want to use for the search pages. It's quite the same as Lucene's settings, but it's a separate page because you can index different fields for Elasticsearch and Lucene.
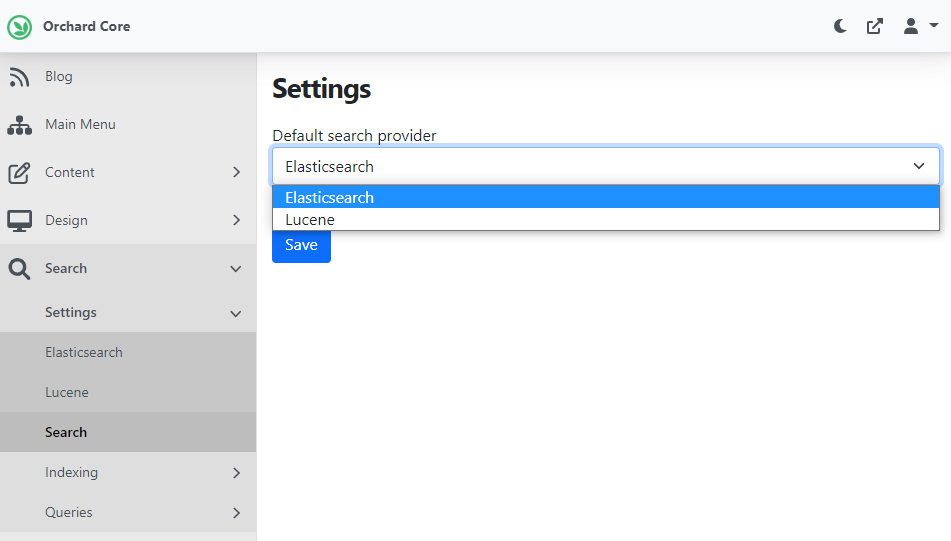
And for the search form, we can decide which provider we want and it will work at runtime. This means you can seamlessly switch from one indexing provider to another one. You can set this up under Search -> Settings -> Search.
If you navigate to the default URL of the search form (/search) you can use this form as you would use it in the case of Lucene. But of course, you need to have an Elasticsearch index that you can use while doing a search and the indices can be set up under Search -> Indexing -> Elasticsearch Indices. As you can see, here we created a new index called default_search and indexed some content types.
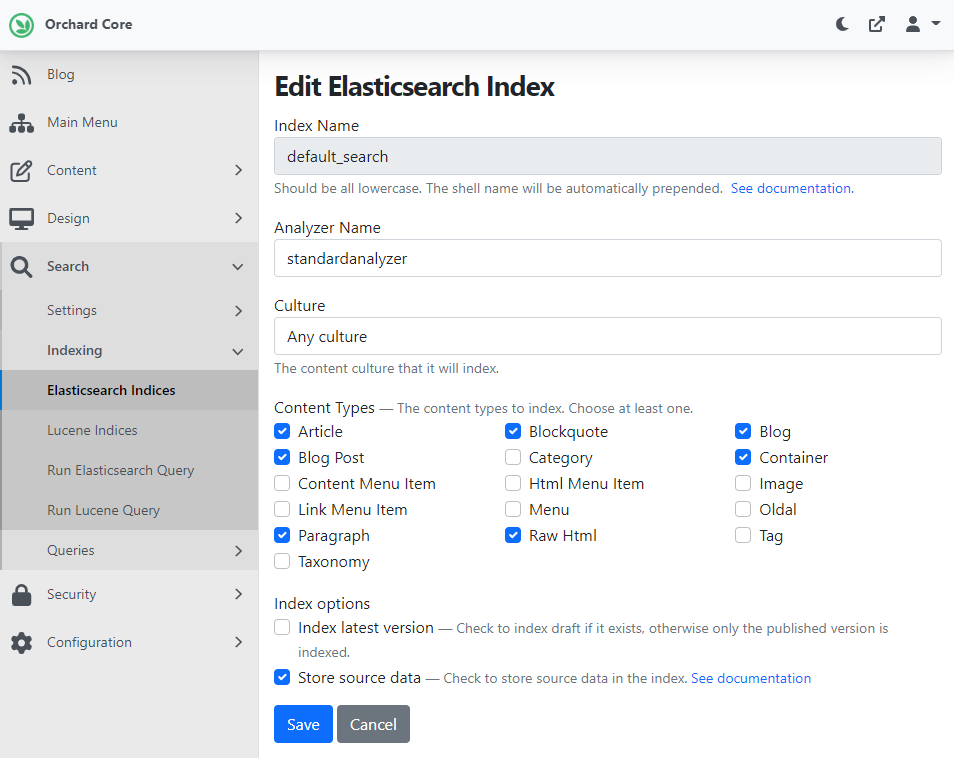
And now, you can use the search form to return results based on your query. The default_search index contains the Article and the Blog Post content types, so if we use the "man OR about" query, the site will return us two results, the default blog post, and the default article content items.
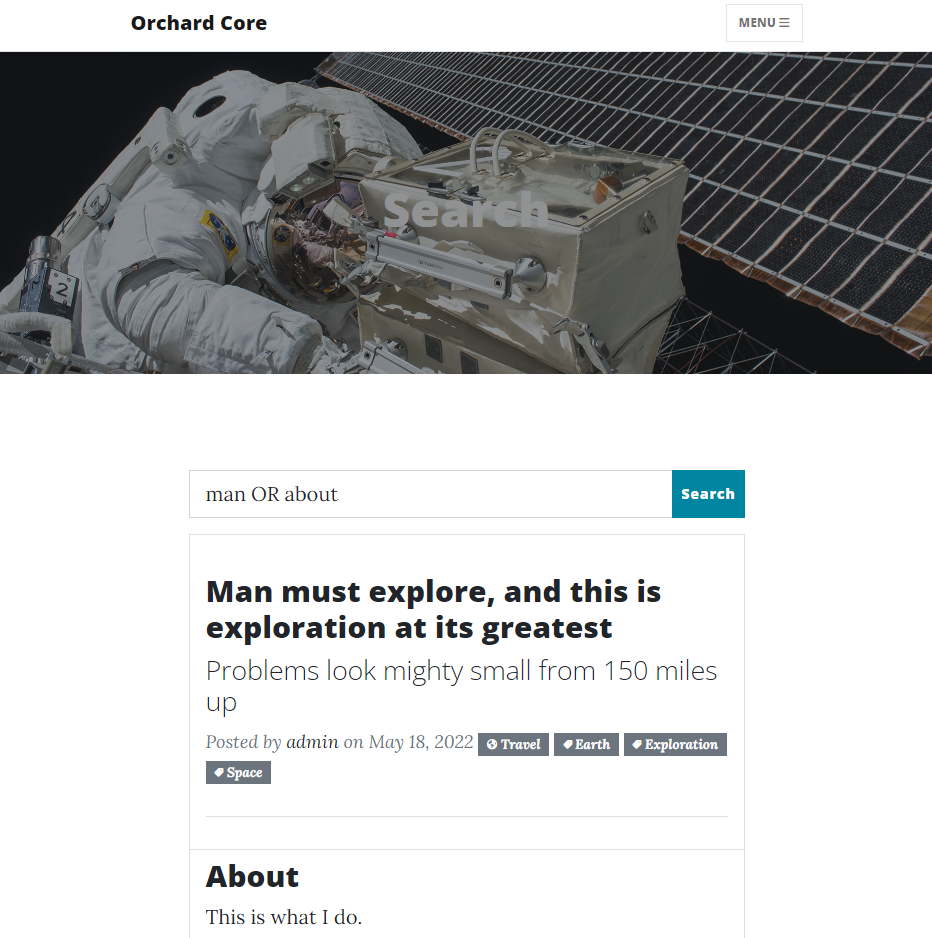
And we are just scratching the surface here. The Readme.md file contains a lot more: how to create an Elasticsearch index during recipe execution, how to create an Elasticsearch query from a Queries recipe step, how to use Web APIs to execute a query, and a lot more! Check out this recording on YouTube if you would like to know more about this upcoming feature!
News from the community
Orchard Dojo Newsletter
Lombiq's Orchard Dojo Newsletter has 341 subscribers! We have started this newsletter to inform the community around Orchard of the latest news about the platform. By subscribing to this newsletter, you will get an e-mail whenever a new post is published to Orchard Dojo, including This week in Orchard of course.
Do you know of other Orchard enthusiasts who you think would like to read our weekly articles? Tell them to subscribe here!